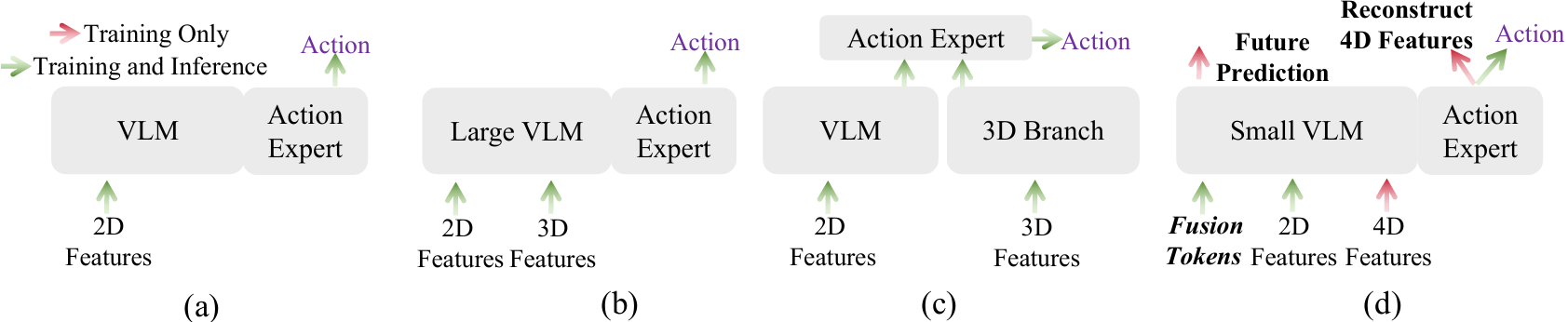
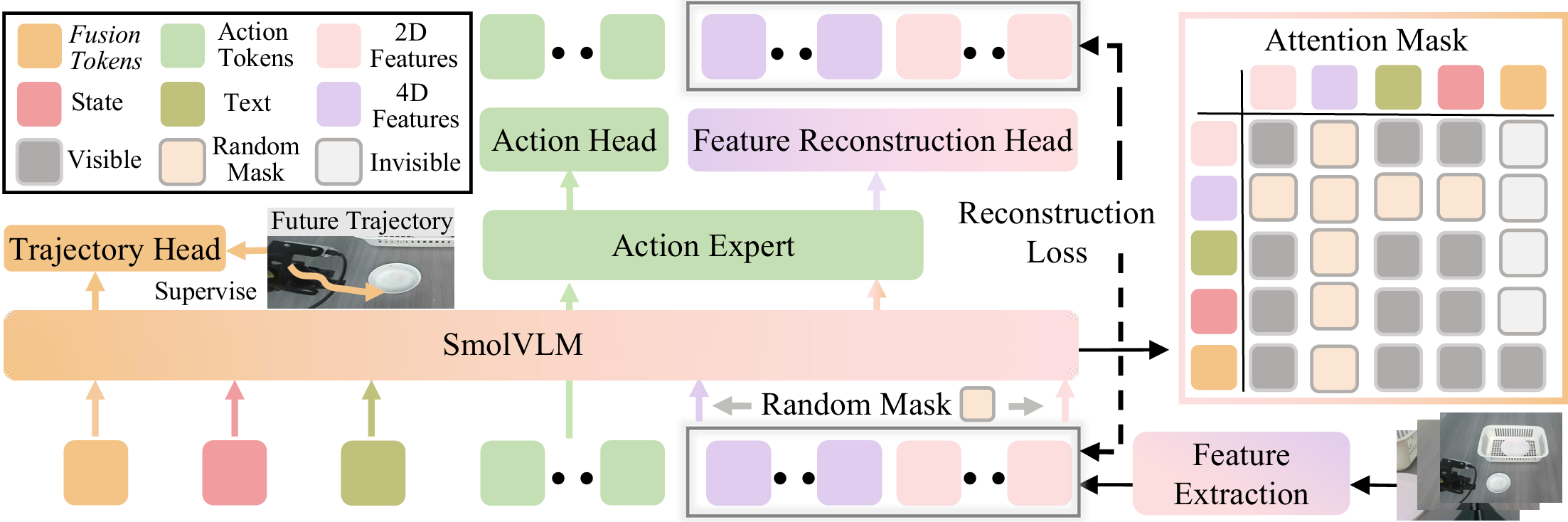
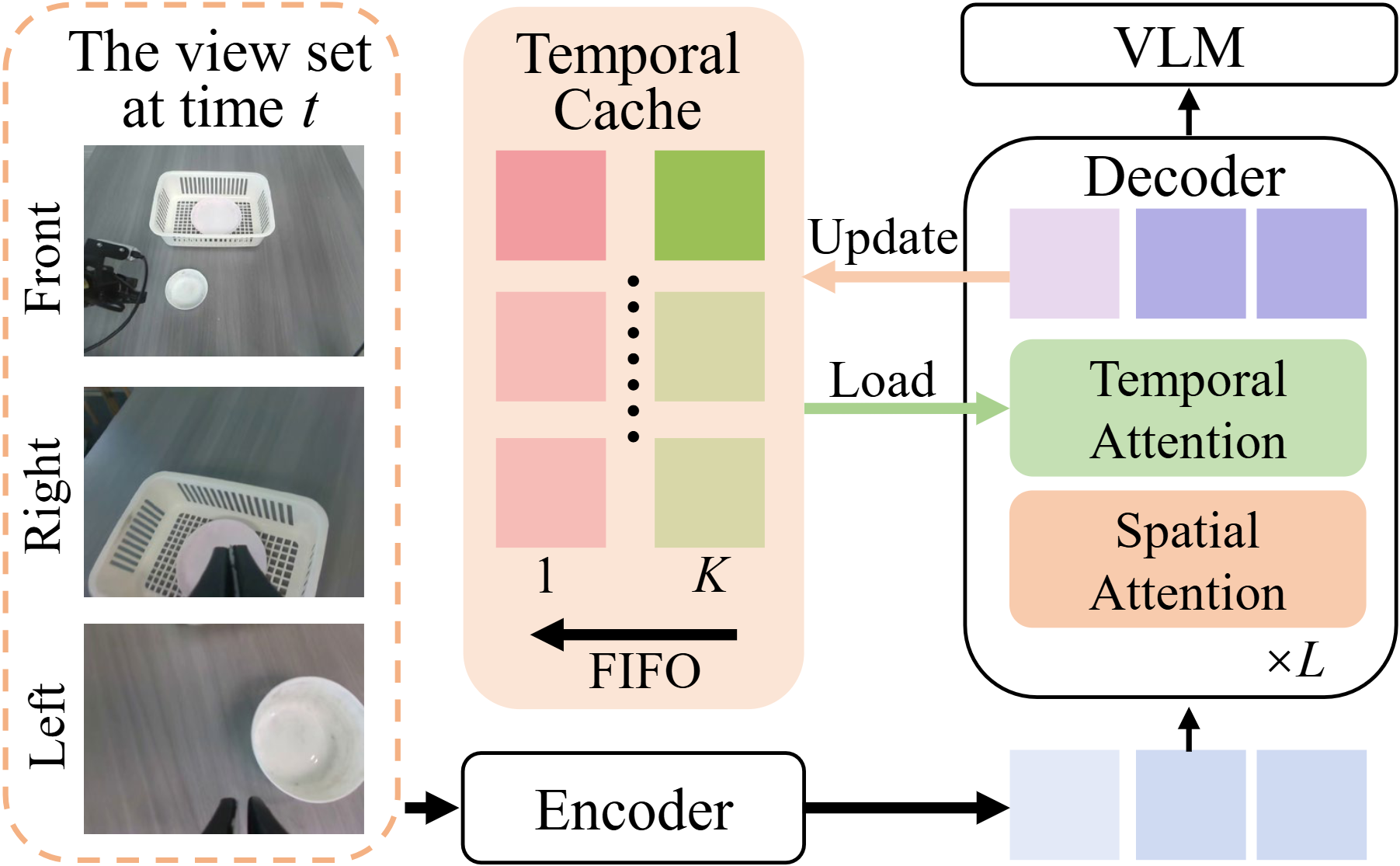
SwiftVLA
SwiftVLA
Unlocking Spatiotemporal Dynamics for Lightweight VLA Models
at Minimal Overhead
Chaojun Ni1,2* Cheng Chen3* Xiaofeng Wang1,4* Zheng Zhu1*†
Wenzhao Zheng4 Boyuan Wang1 Tianrun Chen3† Guosheng Zhao1 Haoyun Li1
Zhehao Dong1,2 Qiang Zhang5 Yun Ye1 Yang Wang1 Guan Huang1 Wenjun Mei2†
1 GigaAI
2 Peking University
3 Moxin (Huzhou) Technology Co., Ltd.
4 Tsinghua University
5 X-Humanoid
* Equal contribution.
† Corresponding author.